# 关于 ELCube
ELCube(逻辑魔方),解决企业变更曲线与软件跟随曲线不匹配的问题。我们追求开发一套快速、 容易的企业级模型方案,让企业更从容,让程序员走出困境。用业务建模的方式解决业务问题, 而不是用技术堆砌的方式绑定企业。
# 相关链接
ELCube 演示系统 (opens new window)
ELCube Front Gitee仓库 (opens new window)
ELCube Front Github仓库 (opens new window)
# 权利声明

ELCube 遵照AGPL-3.0协议开放源代码,在遵照协议约束条件下,您可以自由传播和修改。 协议原文见LICENSE文件,或查阅 http://www.gnu.org/licenses/agpl-3.0.html
# 功能概览
# 技术特性
- 支持任意事务型RDBMS数据库
- 支持JSON格式数据存储及关系型数据库表存储
- 三级缓存设定,redis缓存、应用缓存、ElasticSearch检索,最大化降低数据库IO
- 前后端分离 SpringBoot+Vue架构,兼容SpringCloud微服务
- 支持分布式部署,支持分布式锁,支持多并发业务操作,线程安全
- 支持在线编码、在线运行
- 支持在线多环境调试,多人协作配制
- 支持会话超时下的数据状态保持
- 支持自定义主题
- 前端多标签、多任务
- 支持配置导入导出、一键部署
# 功能特性
- 支持单据配置(复合表单表格结构)
- 支持业务管理功能配置,自定义搜索字段、自定义结果字段(对应数据检索)
- 支持自定义菜单、及搜索条件保存
- 支持业务上下游配置复杂业务流程(业务流)
- 支持工作流审批、会签、工作流管理
- 支持在线绘制工作流程图BPMN,及工作流配置
- 支持权限配置(细颗粒度权限及字段级别数据权限过滤及读写分离权限控制)
- 支持权限限制模式下业务操作数据完整一致性
- 支持数据图表配置
- 支持数据检索导出及文件模板导出
- 支持图形化SQL生成,自定义生成报表及报表下钻
- 支持定制化开发及自定义组件开发
# ELCube是什么
ELCube发源自逻辑魔方内部TS5项目,原本是为融资租赁行业行业开发的行业级解决方案, 通过项目实施经验的积累,我们发现TS5是具备一套适应于其他行业的一套通用开发模型。
# TS5的历史
2008年 国内某融资租赁公司的融资租赁系统上线,恰逢当时金融风暴,国内金融行业非常不乐观, 融资租赁行业也受其牵连,央行连续调息、客户逾期不断,给没有经过任何打磨,通过摸石头过河打造的 业务系统带来巨大考验;这套系统是TS5的前身;
2009年 第三代融资租赁系统代号T3成功上线,T3系统在经历了前一套系统失败的经验后,重新技术 架构,业务流程,完成了从融资租赁全生命周期流程的建设,完善了资金账务管理及变更体系,打通了 银企直联的账务体系,将资金处理从人工转向自动化,这套系统是TS5的业务雏形;
2013年 团队所在的企业全面转向某国际公司大型ERP系统,团队技术转型,成为其ERP系统的实施顾问, 不可否认,国际上领先的思维模式与创新,给团队思想带来了巨大的提升;但国外系统的标准化模块,却因国内 业务的千变万化而水土不服,导致大量功能需要重新定制化开发,在本就不菲的产品价格下,又无形增加了实施的成本;
2019年 技术专项团队成立,对摆脱企业变更速率与软件跟随曲线的不匹配,导致业务系统实施进入困局, 开始结合十年来积累的经验,重新打造一个渐进化的企业级可配置平台,即TS5
2021年 TS5被命名为ELCube,作为开源项目发布
# 绕不开的 低代码平台
近些年低代码开发平台已经成为行业热词,国内有几十家厂商先后推出了他们的产品,其中不乏阿里、腾讯、华为等大厂。 大部分低代码平台官网上的案例主要为:CRM、报销管理、HR、项目管理等轻应用,大部分平台是以灵活的表单、 流程配置为基础。但流程和表单并不是企业业务的基础。行业内没有专门为企业级应用打造的低代码平台。 一般都是厂商提供的各种行业软件;
为什么没有一个企业级系统没有成功的低代码平台案例呢?我们对这个问题进行深刻思考,“让业务人员自己开发”很难在现阶段达到。 软件工程需要具备结构化思维;
因此,ELCube面向的,是开发人员,而不是面向业务人员的低代码平台。我们定位自己为企业级的软件开发范式。
# 面向开发人员的快速开发范式,即开发模型
与其他产品不同的是,我们秉承配置即开发的设计理念,将一些开发工作转换成系统配置工作, 通过配置化的方式实现对系统功能的解耦合,以达到快速实施、快速响应变更的目的。
ELCube是专门为企业级复杂系统而生的技术平台。它具备低代码开发平台的大部分特性, 但它有别于所有的低代码开发平台。在这个平台上我们不仅给出了一套开箱即用的功能, 甚至还重新定义了软件实施方法。
# 适用场景
# 业务管理类系统
- 融资租赁、商业保理、供应链金融等泛金融管理系统
- 催收、准入、用户画像等类风控系统
- 仓储、商场后台等类进销存管理系统
- CRM、HR等常见企业系统
- OA的部分场景,不做深入
# 其他场景
这套架构的能力是足够的,但是是否实际适用,需要各行业专业人士的深度评估后得出结论, 但是我们相信,通过对组件的扩容,它的能力是无限的。
# ELCube 架构介绍
# 领域建模
单据引擎 是系统核心模块,也是领域建模的基础
通过单据引擎建模,我们可以创建出各类结构化的业务单据,这些单据的结构可以具备深层次结构的
单据由状态、卡片、业务规则、索引、数据同步构成
状态:负责控制一个单据的生命周期,即一个业务的生命周期,从创建到审批、直到归档的过程, 不同的状态下,单据可具备不同的业务特性
卡片:负责承载业务数据,不同的卡片具备不同的能力及不同的数据结构,完成单据数据的输入与输出
业务规则:负责单据内卡片之间的数据交互、不同状态下的数据控制、数据输入时的数据计算逻辑等业务逻辑 甚至可以处理不同的业务单据之间的数据交互
索引:单据的数据结构是深层次的,一个单据可能有多个表单,甚至有多个表格,以及嵌套的表格, 通过关系型数据库的表述,就是单据的数据不仅仅只是一个表的一条数据那么简单,因此业务的搜索,是业务系统中 非常重要的一环,索引即是将单据需要检索的字段,通过一定的规则提取,拍扁,形成较为单一,可通过搜索引擎检索的数据格式, 我们通过ElasicSearch完成单据的数据检索工作
数据同步:将单据的数据,进行一定格式的数据转换,输出到另一个存储介质,为数据的再利用做准备,如后续的数据报表、 大数据分析、BI智能、风控等;这也是平常系统开发过程中ETL的工作,我们已经提前做好了。
# 业务流
整个业务系统不仅仅只是对一个表单的输入与输出,而是要负责对整个业务生命周期进行管理。比如一个市场营销的过程, 必然是有 商机->拜访->报价->签约->付款->售后 这样一套业务流程的,甚至业务流程还有分叉,形成一个可以用bpm描述的流程图。
ELCube业务流,是单据引擎的一部分,负责将多个单据,根据业务规则串成一个流程图;
单据负责具体某个业务的具体逻辑,业务流表述具体业务的上下游关系,控制业务从发起到归档的路线。
# 为什么不用bpm描述业务流?
有些系统的做法,是将整个系统用bpm串起来,完成业务生命周期的管理。
我们不采用bpm来管理业务流的原因,是考虑到业务的原子性,在一个漫长业务流程的业务中,每一个单据都是一个原子性, 每个单据本身就有它的生命周期,而业务本身也具有它的生命周期,这种生命周期的管理,就跟现实一样,层层包裹。 我们需要,当一个单据脱离了业务,它仍然具有生命,是现实中事实存在的一个对象,而不依赖与任何其他因素。
# 业务流的特性
- 可变化:业务流随时可以根据业务的需求进行调整,而不必担心版本的问题
- 低耦合:业务流的整个大流程是通过两两单据的对应关系,来形成一个业务整体的,任意两个关联的单据的更改,不影响整个业务流
- 多并发循环:业务流中可以支持同时创建多个单据,或递归、循环创建单据,而不存在锁以及上下文污染的问题
- 多终点:业务的特性是从一个业务入口开始,展开业务分支,最终汇入不同的业务终点,业务流完美具备这些特性
# 审批流
审批流采用bpm,每一个单据都可以配置1个或多个审批流,审批流与业务逻辑隔离。
隔离的好处是职责清晰,单据负责业务的逻辑,bpm负责流程的流转,流程通过控制单据的状态,触发单据的逻辑,来完成整个审批的过程;
基于这些特性,审批流将变得非常简单,甚至不用编码即可完成;
# 数据检索
得益于单据引擎的强大特性,它已经将需要检索的数据帮我们做好了,数据储存在ElasticSearch搜索引擎里面;
通过配置一个搜索界面,就可以完成一个业务功能的管理。
在这个配置中,支持配置字段、格式、搜索条件、排序等常见的功能;
数据条件包括下拉选项、区间检索、日期检索、搜索提示等搜索条件,支持字段排序、分页, 支持动态汇总下拉菜单的选项,及统计选项下可能的结果集数量;
也可以将搜索条件保存起来,方便下一次快速用同样的条件进行检索;
最重要的是,这些基本不需要任何编码,即可完成千万级数据的秒级响应
# 大数据
数据检索功能仅限于对ElasticSearch中的数据进行检索,不能满足复杂数据统计、以及大数据处理的情况;
数据功能是数据检索模块下的深度扩展,在ElasticSearch的基础上增加了ClickHouse等bigtable的数据支持;
通过数据发现功能,业务人员也能自己从各个不同的数据源中挖掘数据,自动生成不同数据源的SQL语法,并形成 可下钻的BI分析报表,也可以将数据结果通过chart进行图形化展示,添加到首页的驾驶舱、或者制作一个DataV的大屏展示。
# 权限粒度
我们采用RBAC模型作为数据权限的基础模型,并增加数据Limit模型作为数据权限模型;
在功能权限层面:
- 支持对不同单据模型进行单独授权
- 支持单据模型下读写不同权的授权
- 支持单据模型不同状态的独立授权
- 支持单据模型下不同卡片的独立授权
- 支持单据模型下不同卡片读写不同权
- 支持数据源的独立授权
- 支持数据源下字段级别的独立授权
在数据权限层面:
- 支持单据中任意字段纬度的授权(包括类组织架构、部门、分子公司等传统方式)
- 支持任意字段级的区间授权
- 支持多纬度排列组合的数据过滤
把各种排列组合列成一个表,大概是这样子
| 场景 | 数据权限 | 读 | 读卡片过滤 | 写 | 写卡片过滤 | 写状态控制 |
|---|---|---|---|---|---|---|
| 没有权限 | ||||||
| 全部读写 | Y | Y | ||||
| 全部读 | Y | |||||
| 全部读&部分卡片 | Y | Y | ||||
| 部分读 | Y | Y | ||||
| 部分读&部分卡片 | Y | Y | Y | |||
| 全部读写&读全部卡片&写部分卡片 | Y | Y | Y | |||
| 全部读写&读部分卡片&写更少卡片 | Y | Y | Y | Y | ||
| 全部读写&写部分卡片&部分目标状态 | Y | Y | Y | Y | ||
| 全部读写&全部卡片&部分目标状态 | Y | Y | Y | |||
| 部分读写&全部卡片&全部目标状态 | Y | Y | Y | |||
| 部分读写&写部分卡片&全部目标状态 | Y | Y | Y | Y | ||
| 部分读写&写部分卡片&全部目标状态 | Y | Y | Y | Y | Y | |
| 全部读写&读部分卡片&写更少卡片&部分目标状态 | Y | Y | Y | Y | Y | |
| 部分读写&读部分卡片&写更少卡片&全部目标状态 | Y | Y | Y | Y | Y | |
| 部分读写&读部分卡片&写更少卡片&全部目标状态 | Y | Y | Y | Y | Y | Y |
得益于单据模型的设计,能支持到如此细粒度授权的,且可自定义的,市面上没有几家吧
# 社区版与专业版没有差异
社区版的功能是完整的,没有阉割的
社区版包含上述介绍的全部内容,且公司专业版也是基于社区版开发的,我们也会持续根据社区版本提供的组件 在演示版系统中搭建更多行业场景的应用;
社区版本中动态表单及动态表格组件,使用得当的情况下足以搭建出一套优秀的可用于生产发布的系统;
开源的组件包中,还包含了很多通用性的卡片,如联动表单、文件上传、文件模板、单据历史、单据镜像、工作流等
甚至,开源组件包中还包含了金融模块卡片,包括还款计划、资金来款、还款核销组件,这些足以完成一套融资租赁管理系统
当然了,作为企业运营的根本,我们仍然需要通过实施项目来完成企业的生存,我们也会持续在专业版中继续开发更多、 更针对细分行业、且适用场景更具体的卡片,来完成特定行业领域的个性化搭建;如果您对专业版本有兴趣, 也可以通过定制服务联系支持我们。
# 定制服务
如果您有深度定制服务的需求,请加入ELCube社区群
# 使用概要
ELCube Backend 为ELCube模型的服务端部分,需要配合ELCube的WEB前端服务一起使用
# 软件架构
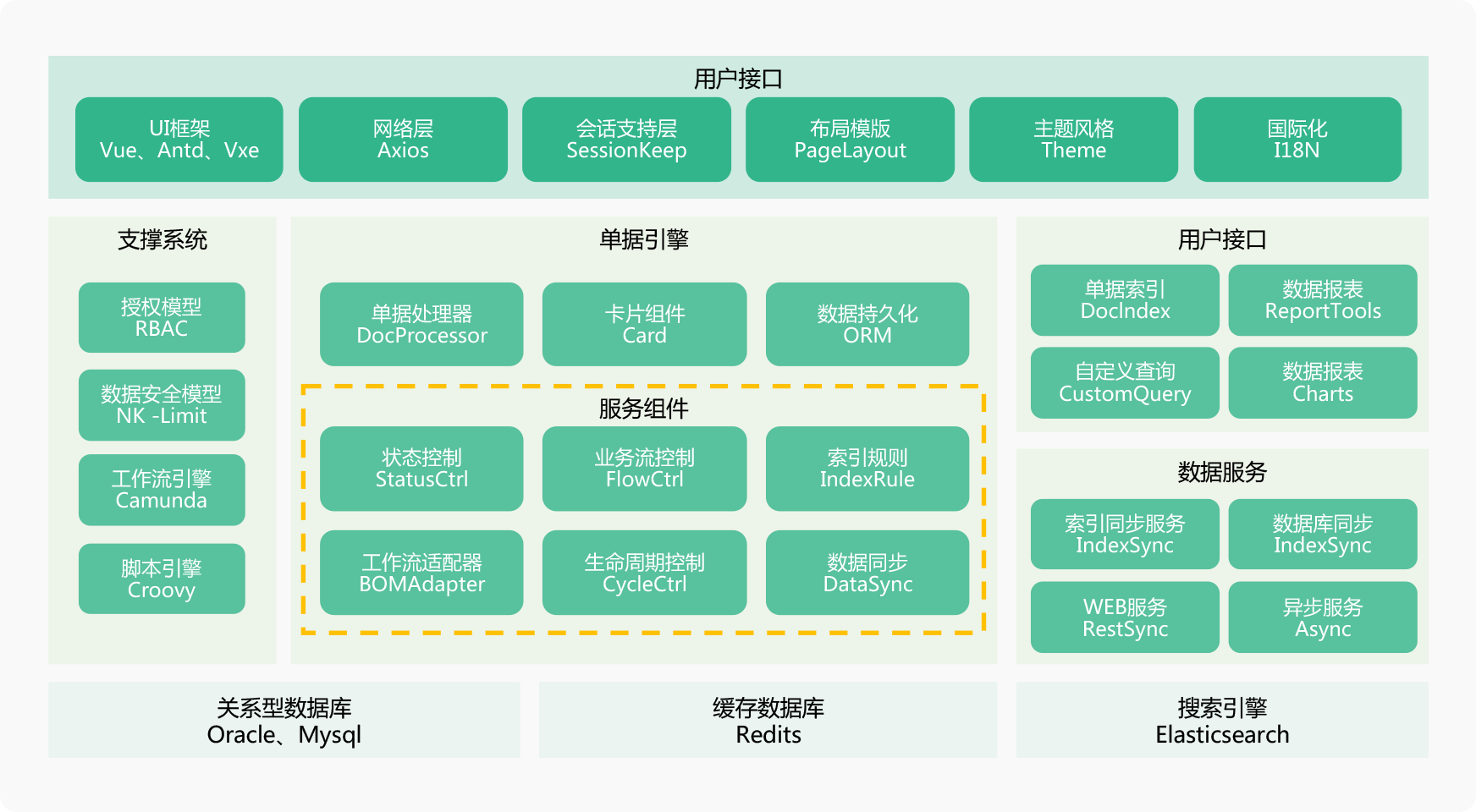
# 安装教程
- 安装JDK
- 安装关系型数据库,如MySQL5
- 安装Redis
- 安装ElasticSearch
- 在application-dev.yml中配置数据库、Redis、ElasticSearch的地址及密钥
- 通过SpringBoot启动程序
- 启动ELCube WEB前端
- 使用初始管理员admin/admin登陆体验
# 参与贡献
- Fork 本仓库
- 新建 Feat_xxx 分支
- 提交代码
- 新建 Pull Request